命令サイクルとCPUの実行仕組み

組み込みソフトウェア開発で処理時間を見積もるとき根拠になるのは、CPUが命令を実行する仕組みそのものです。
一つの命令がCPU内部でどんなステップを経て完了するのか、そのプロセスを押さえておくと、コード設計の段階でこの処理は目標とする処理時間に収まるかを判断しやすくなります。
この記事では、命令サイクルの流れと、それを支えるCPU内部の主要パーツについて扱います。
- なぜ組み込みソフト開発者はCPUの動作を知る必要があるのか
- プログラムは「命令の列」としてメモリに並んでいる
- CPUが命令を処理する3つのステップ
- 命令サイクルを支えるCPU内部の主要パーツ
- 命令サイクルの理解が処理時間の見積もりにつながる

なぜ組み込みソフト開発者はCPUの動作を知る必要があるのか
限られたクロック周波数の中で処理を時間内に収めるには、CPUが命令を実行する仕組みの理解が欠かせません。PCアプリケーションであれば、動作クロックやメモリに余裕があり、必要な処理時間も比較的長めなため、一つの処理にかかるクロック数を強く意識する場面は、あまり多くはないでしょう。
しかし組み込みソフトウェアでは事情が違います。ある処理が何クロックで終わるか、メモリアクセスで待ちが発生しないか。こうした問いに設計段階で答えを出す必要があるからです。
センサの値をミリ秒単位の周期で取得し続ける処理を想定すると、1回のループ(繰り返し処理)に使えるクロック数はごくわずかで、命令サイクルの知識なしに処理時間の概算を見積もるのは難しくなります。この感覚がないまま実装を進めると、テスト工程で処理落ちが見つかり、手戻りにつながりがちです。
プログラムは「命令の列」としてメモリに並んでいる

C言語などで書かれたソースコードは、そのままではCPUに理解できません。ビルド工程を経て機械語に変換され、1命令ずつ隙間なくメモリに配置されて初めて、CPUが扱える状態になります。この並びを先頭から順にたどり、一つずつ取り出して処理していくのが、プログラム実行の基本的な姿です。
組み込みソフトウェアでは、命令の格納先にはフラッシュメモリが使われます。フラッシュメモリは、マイコン内蔵の場合もあれば、マイコンに外付けをする場合もあります。フラッシュメモリ上のコードは、フラッシュメモリ上でそのまま実行される場合もありますし、RAM上に展開されて動作する場合もあります。通常、RAM上に展開されたほうが動作速度は速くなります。
フラッシュメモリの読み出し速度が命令の取得速度にそのまま影響するため、処理時間を見積もる上でも無視できない部分です。

CPUが命令を処理する3つのステップ
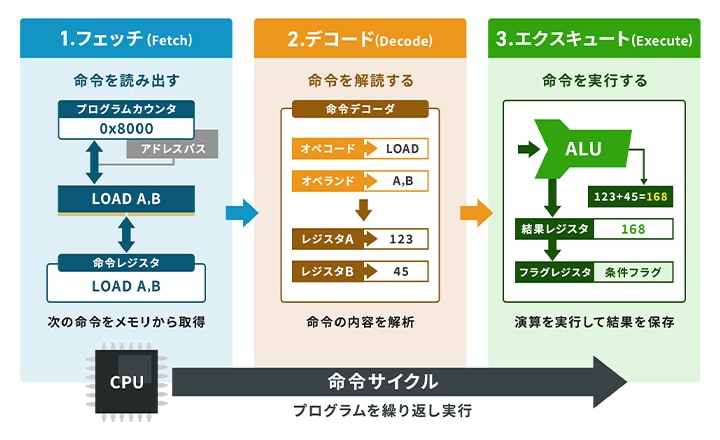
CPUは一つの命令を、以下の3つのステップで処理します。名前だけ見ると難しそうですが、やっていることは意外と単純です。
- フェッチ(Fetch)
- デコード(Decode)
- エクセキュート(Execute)
この一連の流れが命令サイクルであり、CPUはこのサイクルを繰り返すことによってプログラムを実行しています。
フェッチ(Fetch) - プログラムカウンタが次の命令を指し示す
フェッチでは、プログラムカウンタが指すメモリ番地(メモリアドレス)から命令を読み出し、命令レジスタに格納します。プログラムカウンタは次に実行すべき命令の番地を常に保持しているレジスタです。
仮にプログラムカウンタが0x8000番地を指している状態であれば、CPUはアドレスバスを通じて0x8000番地の内容を読み出し、命令レジスタへ送ります。読み出しが済むとプログラムカウンタは自動的に次の番地へ進むため、この時点で次の命令を取得する準備が整った状態です。
命令を取り出すたびにカウンタが先へ進む、この繰り返しがプログラム実行の流れになっています。
デコード(Decode) - 命令の「何を」「どこに」を解読する
デコードでは、命令に含まれるオペコードとオペランドを命令デコーダが解読し、CPUの各部へ制御信号を送ります。オペコードは演算の種類(命令)、オペランドは対象データの所在(アドレス)を示す部分です。
例えばレジスタAとレジスタBの値を加算せよ、という命令が来た場合、オペコードに該当するのは加算、オペランドに該当するのはレジスタA・Bです。デコーダはこれを読み取った上でALUに対して加算の実行を指示し、同時に対象のレジスタからデータを取り出す準備を進めます。
なお、ALUはCPU内部の演算装置のことです。加算・減算・比較演算・論理演算といった基本回路を備え、汎用レジスタ上のデータを対象に処理を行います。
解読の速度はCPUの命令体系に左右される部分です。組み込みで広く使われているRISC型は命令フォーマットが固定長のため、デコーダの回路構造がシンプルに収まり、1クロックで解読が完了しやすい設計になっています。
エクセキュート(Execute) - ALUが演算を実行する
エクセキュートでは、ALUがデコーダの指示に従って演算を実行し、結果をレジスタに格納します。
温度センサから取得した値が、上限を超えていないかを判定する場面を想定してみましょう。この場合、汎用レジスタに格納されたセンサ値と、あらかじめ設定した閾値である80℃をALUが比較し、結果はフラグレジスタに反映されます。
加算や減算であれば演算結果そのものが汎用レジスタに書き戻されますが、比較演算の場合にはフラグの変化が主な出力です。この結果を次の分岐命令が見て、アラームを鳴らすかセンサ値の読み取りを続けるかが決まります。
こうした比較と分岐の組み合わせは、組み込みシステムの制御ロジックで頻繁に登場します。比較命令一つで3ステップ分のクロックがかかる、という感覚は持っておいて損はないでしょう。
命令サイクルを支えるCPU内部の主要パーツ
ここまで見てきたフェッチ・デコード・エクセキュートの各ステップは、CPU内部の複数のパーツが連携することで成り立っています。命令サイクルを支える主要なパーツは以下の通りです。
- レジスタ
- ALU(演算装置)とバス
それぞれの役割と、命令サイクルとの関わりについて説明します。
レジスタ - CPU内部の高速な一時記憶領域
メモリと比べると容量はごくわずかですが、CPUが1クロックでアクセスできる記憶領域がレジスタです。命令サイクルの全てのステップで経由するため、CPUにとっては最も身近なデータ置き場といえます。
主要なものを挙げると、まずフェッチ〜エクセキュートの流れに直接登場するのがプログラムカウンタ、命令レジスタ、汎用レジスタの3つです。プログラムカウンタは次の命令番地、命令レジスタはフェッチで取得した命令、汎用レジスタは演算対象や結果をそれぞれ保持します。
また、レジスタには比較演算や桁あふれの状態を記録するフラグレジスタ、スタック領域の現在位置を管理するスタックポインタなどもあります。
組み込みシステムでは使用可能なRAM領域が限られるため、スタックポインタが指す領域の設計は早い段階から気を配っておきたいところです。
ALU(演算装置)とバス
前述の通りALUはCPU内部の演算装置で、汎用レジスタ上のデータに対して演算を実行します。そして、このALUとレジスタ、メモリの間をつないでデータや命令を運ぶ通路がバスです。
バスにはアドレスバス・データバス・制御バス(コントロールバス)の3種類があります。アドレスバスはアクセス先のメモリ番地を指定し、データバスは命令やデータの実体を運び、制御バスは読み出し・書き込みなど動作の種別を伝える役割です。
また、バスの構成方法にはノイマン型とハーバード型があります。ノイマン型は命令とデータでバスを共有しますが、ハーバード型ではそれぞれ専用のバスを持つため、命令の読み出しとデータの読み書きを同時に進められるのが特徴です。
組み込みシステムではクロック数に余裕がない分、これらの同時実行ができるハーバード型が広く採用されています。
命令サイクルの理解が処理時間の見積もりにつながる
命令サイクルのプロセスを理解することにより、処理にかかるクロック数をコード設計の段階で概算できます。CPUはクロック信号に同期して動作しますが、一つの命令に必要なクロック数は一律ではありません。
この値はCPI(Cycles Per Instruction)と呼ばれ、単純な加算なら1クロックで完了する一方、除算のように内部で複数ステップを要する命令では数クロック以上かかります。
加えて、メモリアクセス時にはウェイトと呼ばれる待ち時間が発生する場合があります。フラッシュメモリから命令を読み出す際にCPU側の動作速度にメモリの応答が追いつかず、数クロック分の空白が生じるケースはその典型です。キャッシュを使用している場合は、使用するときと使用しないときとで処理時間が大きく変わります。これらの処理時間に空白ができる要素はよく考えて調べて置かないと処理性能が大きく変わってしまいます。
このように処理時間の見積もりは、CPIだけでなくこうしたウェイトまで含めて初めて高い精度が出ます。実機で動かす前にこの概算が高精度にできるかどうかで、設計段階での判断の確度は大きく変わるでしょう。
合わせて、実装したコードの処理にどの程度時間がかかるか、早い段階で計測しておくことも重要です。実際のマイコンでの時間計測を行うことで、どの程度処理時間に余裕があるかがわかります。
