通信におけるI/Oの堅牢化とタイムアウト設計
組み込み機器の通信は、ノイズの混入やケーブルの抜け、相手機器の不調といった異常と隣り合わせです。こうした異常時に応答を待ち続けると、タスクが停止し、機器全体が動かなくなりかねません。本記事では、通信が滞ったときに機器を守るタイムアウトとリトライの設計を解説します。時間の決め方からバックオフ、遮断と復帰、実装時の確認点までが対象です。

タイムアウト/リトライ設計の重要性
組み込み機器を安定して動かすには、通信異常が起きる前提で設計する視点が欠かせません。なぜ単純な再試行では足りず、どのような観点で堅牢性を組み立てるべきなのか、その土台をまず整理しておきましょう。
組み込み機器で生じる通信異常
産業機器や工場の自動化を担うFA機器は、機器の間の通信ではRS232やRS485、Etheretなどを、機器の内部ではUARTやSPI、I2Cなどといった通信路を使います。これらの通信路では、ノイズの混入やケーブルの断線、相手機器の未接続によって応答が返らず、待ち状態に陥りがちです。
IPAの高信頼化教訓集でも、通信途絶を起点とした不具合事例が報告されています。現場で求められるのは、異常時でも機器が動き続けることです。
再試行だけでは不十分な理由
通信が失敗したとき、単純に再送を繰り返すだけでは問題を広げかねません。複数の機器が一斉に再送すると通信路が混み合ったり、通信同士がかちあうことで輻輳がさらに悪化します。相手の機器が故障している間は、再試行を繰り返しても応答のない通信にCPU時間を浪費してしまいます。
NISTの脆弱性データベースにも、応答処理の不備で通信データが無制限に蓄積し、過負荷に陥る脆弱性が登録されています。再試行の間隔を調整する、または再試行を止めるタイミングを適切に見極める設計が問われるのです。
堅牢性を高める設計で考慮すべき観点
堅牢な通信処理は、複数の観点を組みあわせてはじめて成り立ちます。具体的には、タイムアウト時間、リトライ回数、復帰の条件、障害を切り分けるためのログ設計です。IPAの設計ガイドでも、異常系を含めた検証の大切さが示されています。これらをばらばらに扱わず、一つの方針として束ねる姿勢が大切でしょう。次章から各観点を掘り下げます。
タイムアウトの基本設計
タイムアウトは勘で決めるものではなく、根拠をもって算出するものです。適切なタイムアウト時間の決め方に加え、無限に続く応答待ちを防ぐ設計やウォッチドッグタイマとの使い分けまでが設計の要点になります。
タイムアウト時間の設定
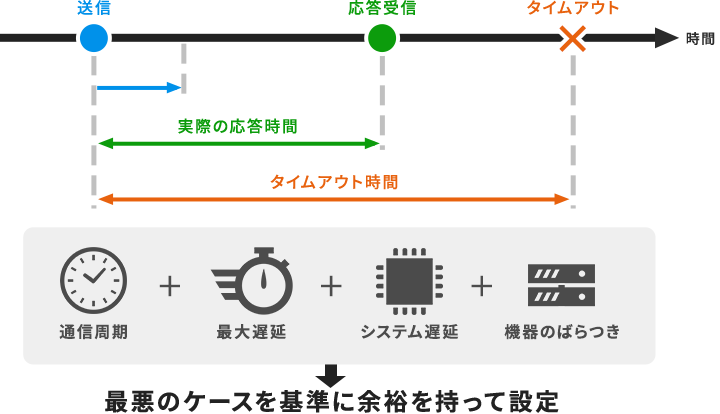
タイムアウト時間は、通信周期と最大遅延時間から算出するのが基本です。基準とすべきは平均応答時間ではなく、処理が最も長くかかる最悪実行時間に置きます。平均値で決めると、正常な範囲の遅延まで異常と誤って判定しかねません。CPUの負荷やOSのスケジューリング遅延、外部機器のタイミングも加味しましょう。
無限に続く待ちを防ぐ設計
応答を待つ処理には、必ず監視時間を設けます。ポーリングで状態を読み続ける場合は、待ちの上限をあらかじめ決めておくべきです。リアルタイムOSを使うなら、待ちのAPIにタイムアウトを指定しておきましょう。CPUを介さずデータを転送するDMAの完了通知が来ない場合でも、割り込みが来ないときに抜ける異常系を用意します。離脱できない待ちを残さない姿勢が肝心です。
ウォッチドッグとの役割分担
ウォッチドッグタイマは、一定時間内に信号が届かないとシステムの異常を検出して動作します。局所的な異常からの回復にはタイムアウト、システム全体の停止検出にはウォッチドッグと、役割を分けて使うのが基本です。
複数のマイコンメーカーのアプリケーションノートでも、両者を組み合わせた設計が示されています。通信異常が起きてもすぐに機器を再起動させず、段階的な復旧をまず試みるべきでしょう。

リトライ設計とバックオフ
リトライは、回数だけでなく再送の間隔をどう設計するかが成否の分かれ目です。一定間隔の再送がなぜ危ういのかを起点に、間隔を伸ばす指数バックオフ、ばらつきを与えるジッターへと話を進めます。
固定間隔、固定回数のリトライにより生じる問題
一定間隔で同じ回数だけ再送する設計は、手軽ですが負担が大きくなりがちです。多数の機器が同じ周期で再送すると、信号が集中して通信路を圧迫します。場合によっては、1つの通信路上で信号がかちあい、再送自体が届かないこともあります。停止した相手機器に対しては、無駄な負荷をかけ続けるだけです。バッテリで動く機器では、消費電力の増加も見過ごせません。
指数バックオフの実装
指数バックオフは、再送のたびに待機時間を段階的に長くしていく手法です。待ち時間を1秒、2秒、4秒と倍に増やす方法は一例です。こうすれば、復旧までの間、相手機器を過剰な通信から守れるでしょう。一時的な障害からの復旧成功率が上がる点も利点です。クラウドサービスの公式ドキュメントでも、リトライの定番手法として推奨されています。
ジッター(Jitter/ゆらぎ)の導入による負荷分散
指数バックオフだけでは、待機時間が同じになった機器どうしが再び一斉に通信しかねません。そこで、待機時間に乱数による小さなゆらぎを加えるのがジッターです。再送のタイミングがばらけるため、瞬間的な負荷の集中を防げます。多数の端末がサーバへ同時接続する状況では、サーバ保護に特に有効でしょう。
遮断と復帰の設計による通信I/Oの堅牢化
リトライを工夫しても直らない異常には、別の対応が必要です。異常時に通信を止める判断や設計、止めた通信を安全に戻す手順、状態遷移による管理の方法を取り上げます。
異常時には通信を止める設計
相手機器の故障が疑われるときは、通信を一時的に遮断します。重要なのは、永久的な故障と一時的な故障の切り分けです。一定回数の失敗が続いたら通信を遮断する仕組みは、サーキットブレーカーと呼ばれます。異常を検知すると回路を開いて通信を止めることで、CPU時間の浪費や暴走の連鎖を抑えられるのです。その間に、安全な状態でシステムを停止させるような動作をすることができます。
段階的な復帰手段の設計
遮断した通信を戻すときは、一気に元へ戻さず段階を踏みます。一定時間が経過したら再接続を試み、初回は少量の通信で疎通を確かめるとよいでしょう。ウォーミングアップの通信を挟むと、安全に復帰できます。複数の機器が関わる場合は、電源を再投入する順序にも気を配りましょう。こういった、復帰時の手順は、システムのルールとして設計し、それぞれの機器がそれを守れることを確認するようなテストも必要になります。
状態遷移による異常の管理
通信の状態を整理しておくと、復帰の判断がぶれにくくなるはずです。たとえば、正常を表すNORMAL、再試行中のRETRY、遮断中のBLOCK、復帰中のRECOVERYの4状態を定義します。サーキットブレーカーの解説でも、通常と遮断、回復確認の3状態で管理する考え方が基本です。状態遷移図を用いて、どの条件でどの状態へ移るかを明示します。
実装時の確認ポイント
設計した仕組みを現場で機能させる上で、重要なポイントが3つあります。障害解析を支えるログの設計、リトライを品質劣化の兆候と捉える視点、異常系テストの要点を最後に押さえます。
ログ設計の重要性
障害の原因を切り分ける上で、適切なログは重要な情報源です。タイムアウトの発生回数や復帰の成功率、最終的なエラーの原因を記録しておくことが欠かせません。特にウォッチドッグが作動した場合、その理由を残さなければ、後の原因究明で重要な手がかりを失います。記録は後から解析しやすい形式でまとめることが大切です。
リトライは一時障害の兆候
リトライが成功したとき、それを正常と捉えてはいけません。再送して通信できたという事実は、一時的な障害が起きていた兆候です。リトライの回数や頻度を監視対象にすれば、通信品質が悪化する予兆を早めにつかめます。集めた記録は、保守の貴重なデータにもなるでしょう。
テストによる異常系の確認が不可欠
設計した異常時の動きは、テストで確かめないかぎり机上の想定にすぎません。代表的な手法はケーブルの抜去、遅延の注入、パケットの欠落、長時間の連続動作試験です。ソフトウェア、ハードウェア双方の知識が必要なため、難しいテストになりますが、異常系の確認をやり切ることが、堅牢な機器づくりの仕上げになります。
